Building a Custom Twitter Scheduler with Markdown Support
Wouldn't it be great if you could write with Markdown on Twitter, with code blocks and proper syntax highlighting?
Well, I built myself a tool that does just that.
It also schedules my tweets so I can write in batches, among other things.
In this article I want to share how I built this tool, along with some interesting challenges and things I've learned while implementing it.
Let me know — what would you have done differently when building this system?
But first, why did I even do this?
There are plenty of tools out there to schedule tweets, so why did I build my own?
Besides the fact that building stuff is fun:
- Markdown support — I like writing in Markdown, especially if I have to format code examples. Everything else I do is in Markdown, so it’s nice to have my Twitter writing also support Markdown.
- Integrate with custom tools — Beyond just Markdown, I have other tooling I’ve built to help me with writing my newsletters and tweets. This tool bridges the gap between my existing tools and Twitter.
- Other custom features — There are lots of other custom features I’d like to add. For example, automating retweets. It’s fairly common practice to retweet something a few hours after you’ve tweeted it. This increases the chances someone will see it, since Twitter’s algorithm is heavily biased towards recent tweets.
- A chance to learn — My job is to teach you things, which implies that I also have to learn things. There’s no better way to learn than to build something for yourself. A close second is to pay someone else (eg. me) to distill months of their learning into a format you can consume in mere hours.
Architectural Overview
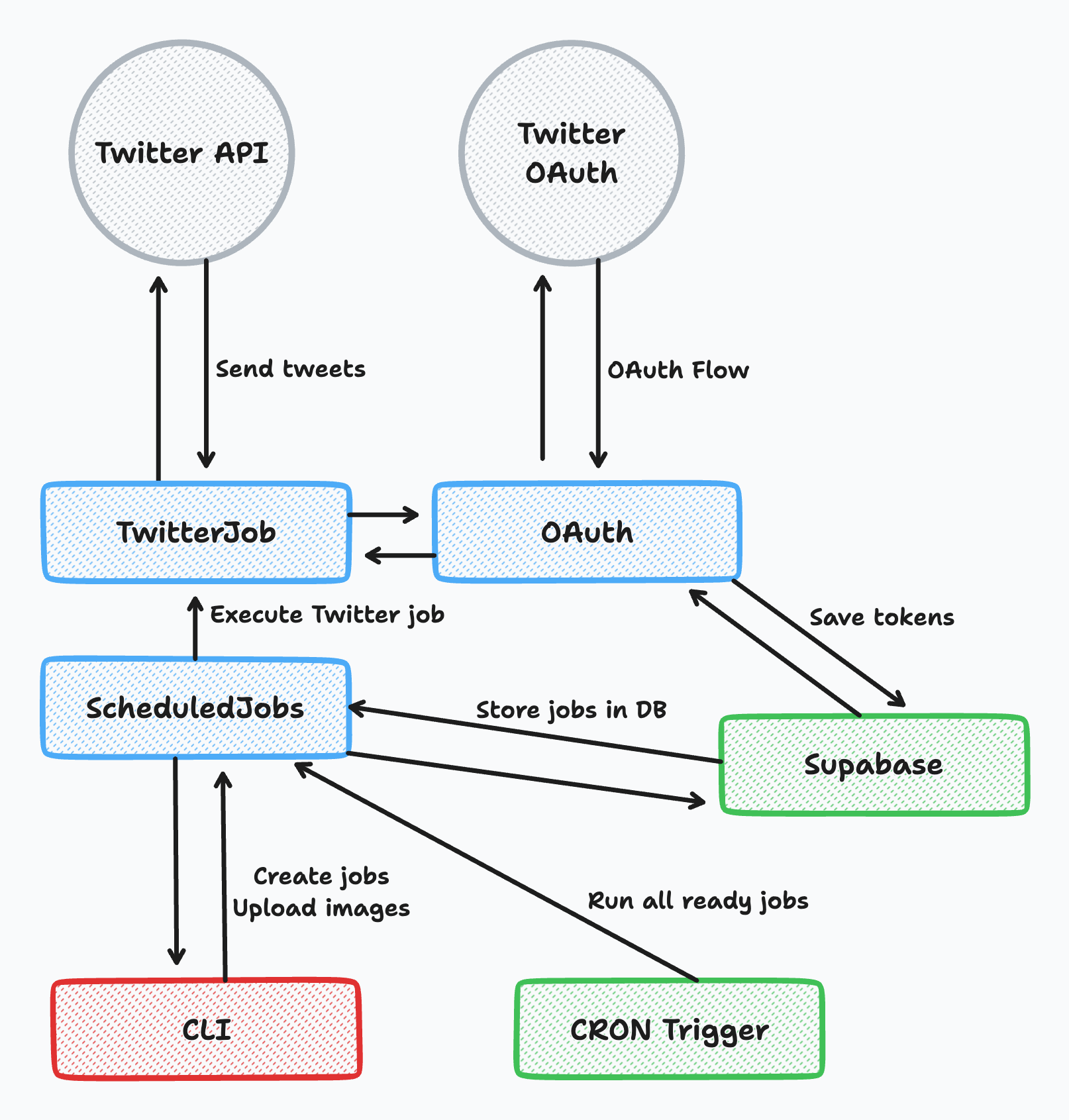
Here’s a quick overview of the system and it’s main components before we look at each one in more detail:
- Scheduling Jobs — This is the backbone of the whole system. This lets me run this service in the cloud 24/7.
- OAuth — So I can authenticate with Twitter, or any other service I want to authenticate on my behalf. I actually ended up doing this in two separate ways, but we’ll get to that later.
- Twitter Job — This is the part that actually interacts with the Twitter API by sending tweets into the void (where some of you may eventually read them).
- CLI — I need some sort of interface to interact with my new tool, and building a full UI is overkill. This bridges the gap between my mess of scripts and my shiny new API.
Scheduling Generic Jobs
I created a generic job scheduler to solve two main things:
- Schedule tweets in the future — I discovered very early on that batching my tweet writing is extremely effective. I can get more done, but I’m also less likely to get distracted by Twitter if I’m not on it as much.
- Handle any generic jobs — Right now it only sends tweets, but I can build on this to add any feature I want. Before I mentioned auto-retweeting or quote tweeting my own tweets a few hours after the initial tweet. However, I can create jobs for anything now — sending emails, pulling in data from Stripe to calculate things for my accountant etc.
Running Code on a Schedule
I host all my things on Netlify, and luckily for me, they have a cron feature built-in called Scheduled Functions. However, the way that Nitro builds the server means that there is only a single lambda function created. This means I can’t configure Netlify to trigger a specific endpoint on a schedule.
To get around this, I created a bare-bones project that acts as a proxy between Netlify’s scheduling and my own server. It has only this single function in it:
There are more robust, enterprise-grade solutions for cron job triggers, but this solution is free and simple. It only took me 15 minutes to write and deploy.
Creating and Storing Jobs
Here’s the current Prisma schema for my scheduled jobs:
I’m using a generic payload field so that each JobType can specify it’s own types. These types are enforced when creating the job.
Each job has three potential states — PENDING, SUCCEEDED, or FAILED. When running jobs, we look for PENDING jobs which have a scheduled time in the last hour. This creates a sort of pseudo-retry logic if the exact time was missed for some reason, but prevents something from running way after it was intended to.
Make it rock solid — make it easy to test
The scheduler is the riskiest part of the whole project. If it goes haywire, it could send the same tweet every 5 minutes indefinitely, which is what I would consider a catastrophic failure. If that happened, how could I ever show my face on Twitter again?
In order to write lots of tests, I made sure to extract all of this scheduler logic into a client file. It’s just a plain TS file that can be used anywhere else I need it.
By keeping code highly modular like this we get several benefits.
First, my API endpoints now look like this:
They’re extremely simple and probably not even worth testing. Which is great, because to test these endpoints would require spinning up an entire server for each test run, which is very slow and very annoying.
Which leads me to the second benefit — all the actual business logic is now a collection of easy-to-test TypeScript methods with nothing fancy going on.
Dealing with OAuth
Implementing OAuth isn’t so bad — if you’ve done it before.
But the first time I did this it took me a very long time to wrap my head around what was going on, why we needed all these tokens, and why it was even necessary in the first place. If you want a primer on OAuth, I’ve written about it before.
Here, I’d like to cover some of the interesting parts of my implementation for this project.
Using Nitro storage for profit
I’m using the twitter-api-v2 package, and although it abstracts a few parts of the OAuth process for us, we still have to hook everything up.
Part of the Twitter OAuth flow requires us to keep a state value and codeVerifier that’s used in two requests:
/oauth— here we create the two values, save them, and then redirect to the OAuth provider and pass along thestate/callback— the OAuth provider redirects back to us, and we check that it’s the samestatevalue to verify nothing funny happened in between. We also receive acodethat we need to verify with thecodeVerifier.
Since we only need to save these values temporarily between requests, saving them to a DB is unnecessary. Nitro, the server that Nuxt uses internally, comes with a handy storage abstraction that makes this really simple for us.
Here’s the entire event handler for the /oauth endpoint as I’ve implemented it:
A single line and we’ve saved the state value to the filesystem.
In the /callback handler, the very first thing we do is grab this value:
We then use the codeVerifier we created in the /oauth handler to verify the code value given to use in the /callback handler.
More OAuth
I was so happy that my OAuth v2.0 implementation was working well — and fully tested!
Then I discovered that to upload images to Twitter’s API, you need to authenticate using the older OAuth v1.0 flow. Twitter has not updated their API to use a universal authentication system 🙄.
Luckily, the processes are similar enough that I could reuse most of the code pretty easily. But now I have two models in order to store OAuth tokens in my database:
Most services these days use OAuth v2, which has a standard token format.
I added in a client and username field so I can easily add new services and multiple users. It’s not gold-plating at all, since it doesn’t change the implementation that much. Already, it’s come in handy for testing with a test account (you didn’t think I’d spam thousands of people with “test. testingggg” tweets, did you?).
Posting to Twitter
Now that authentication is figured out, the next step is to actually send tweets!
Twitter Client
The Twitter client is very straightforward, and essentially has one main function, executeJob. When a Twitter job is executed, this method is passed the payload from the database which contains all of the tweet data.
First, we grab an authenticated Twitter client for the user we need to tweet for, and then we upload all the images.
Uploading images to Twitter
Lots of my tweets include screenshots of code, so I need to be able to post tweets with images, not just plain text.
At first I uploaded directly to Twitter to keep things simple. I kept getting mysterious 400 errors when posting tweets, with no additional error message — super helpful, I know! Eventually I realized that Twitter very quickly deletes images that aren’t attached to any published tweets.
The solution is pretty simple though. I use Supabase storage to store the images temporarily, using the CLI to upload images there first when I schedule my tweets.
When a tweet job is executed, we first download the image from Supabase, then upload it to Twitter. We post our tweet immediately after, so the images are never deleted and we no longer get mysterious error messages.
However, to upload images to Twitter, we have to use a separate OAuth process. This is why I have to use the v1ClientForUser method in the uploadMediaToTwitter method.
Next steps for this project
This project is in a good spot for now, but there are some things I’d like to work on next:
- Auto-retweet logic, configurable per tweet type
- Moving more tools into my CLI
I’d love to know your thoughts on this project:
- What would you do differently than me?
- Are there parts you want to hear more about?
Let me know on Twitter or through email — this is a very different kind of post than I usually write!